
This post builds upon a newly released academic research: From FinTech to TechFin: The Regulatory Challenges of Data-Driven Finance
Data is the new oil fueling the next economic transition. While the 21st century reaches a tipping point, few questions remain: Will winners be a financial (FinTech) or data intermediary (TechFin)? Will business model with interest bearing income or fee generating revenues create the most valuable companies? Who will be the ultimate owner of this digital oil?
The list goes on, and for now, there is one certainty: technology groups are more valuable than financial and oil companies… combined! (See graph below). Let’s understand why.
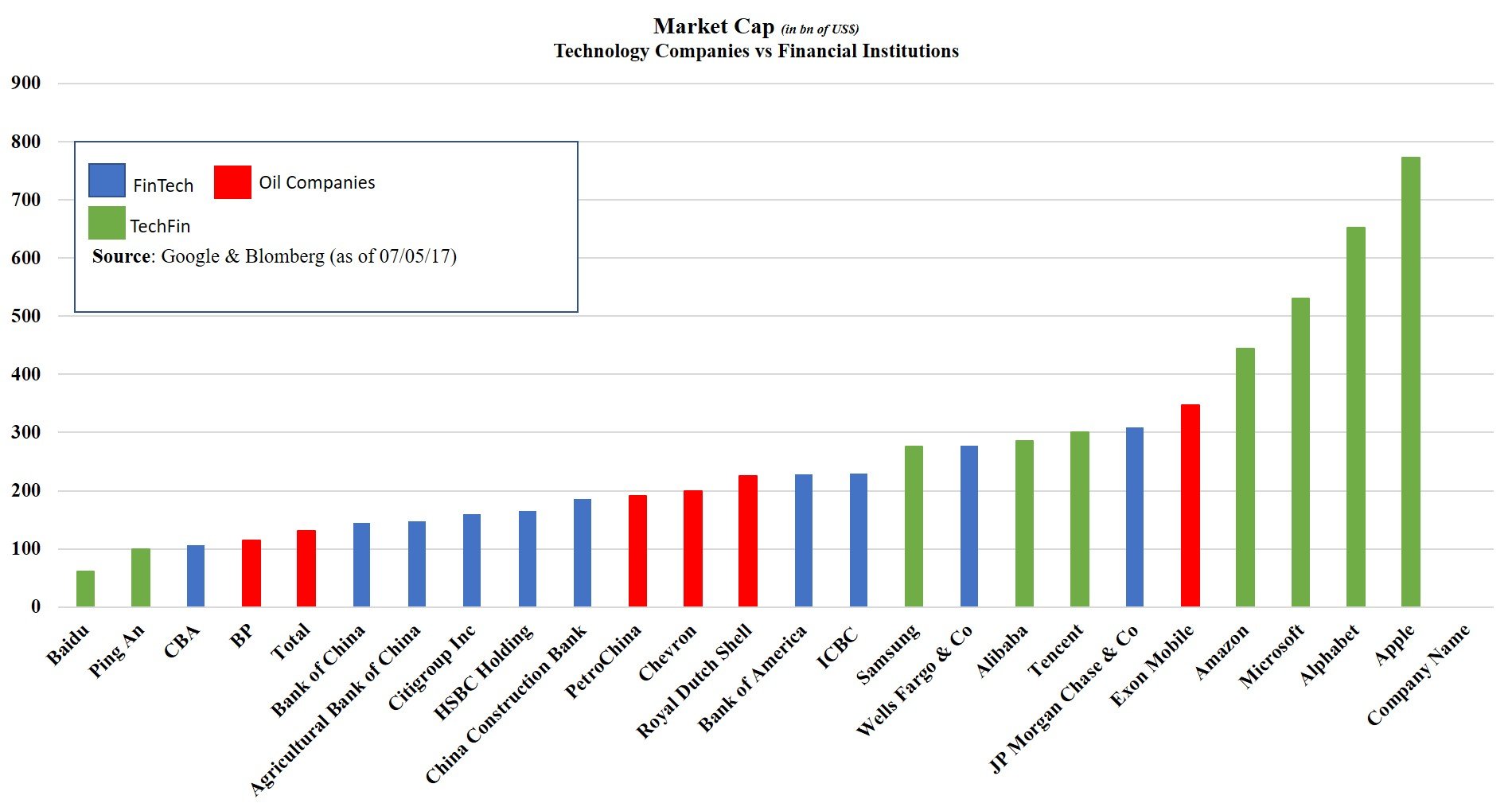
Therefore, this blog starts by breaking this FinTech/TechFin divide. Additionally, their data briefing was too US-Centric. So, an Asian perspective will be brought forth.
I will argue three different points, each centered around a previously published thesis: The next economic (r)evolution will emerge at the juncture of financial regulation, digital identity, and data management:
- The Data Paradox: The problematic valuation of abundance (hint: you are not worth what you think you are)
- Differential Content vs. Context: The origins of privacy law limitation (hint: “tell me what you do, and I will tell you who you are” is a regulatory arbitrage)
- Data Ownership: Incentivization of market participants and the rule of law (hint: you will understand my use 1850’s pictures, trivia knowledge guaranteed)
This blog hopes to start a longer debate whose outcome has yet to be defined. Indeed, paradoxes in need of solutions are beginning to emerge. Digital data is becoming increasingly subject to physical walls (i.e., Draft Security Measure in China or Russia’s Yarovaya Law signed in 2016 and blocked WeChat today). Finally, data ownership is at a crossroads. On one side, the Western vision of data sovereignty is set in the GDPR. On the other, the US recent repeal of FCC privacy rules gives data to internet service providers (ISP) instead.
The key takeaway can be summarized in this simple sentence:
If data is the new oil and data sovereignty the new norm, this will lead to an unprecedented oil rush in building a digital economy
The Data Paradox: Most Valuable Commoditized Asset
Data is the new asset used and created by technology companies. Unlike oil, data is increasingly abundant to the point that 90% of the world’s data has been created in the last two years. Whereas fossil fuel is finite, data availability seems infinite. Moreover, this trend will only accelerate, with 1.5bn smartphone sold this year and an expected 20bn IoT devices by 2020.
What is the direct consequence of this new wealth of data? Put bluntly, your data is worth only a fraction of your estimate. According to a 2013 survey, people expect that to be around US$4,200.
In 2000, marketers would pay upward of US$100/person for demographic details such as age, gender, location, and income. In 2013, marketers paid US$0.0005/person. Best part? Being a millionaire only adds US$0.1 to your worth, working as a financial executive adds US$0.07, having recently been married is US$0.01 and US$0.2/known medical condition. It seems that in the digital age, the 99% and top 1% share the fate of being priced under US$1.
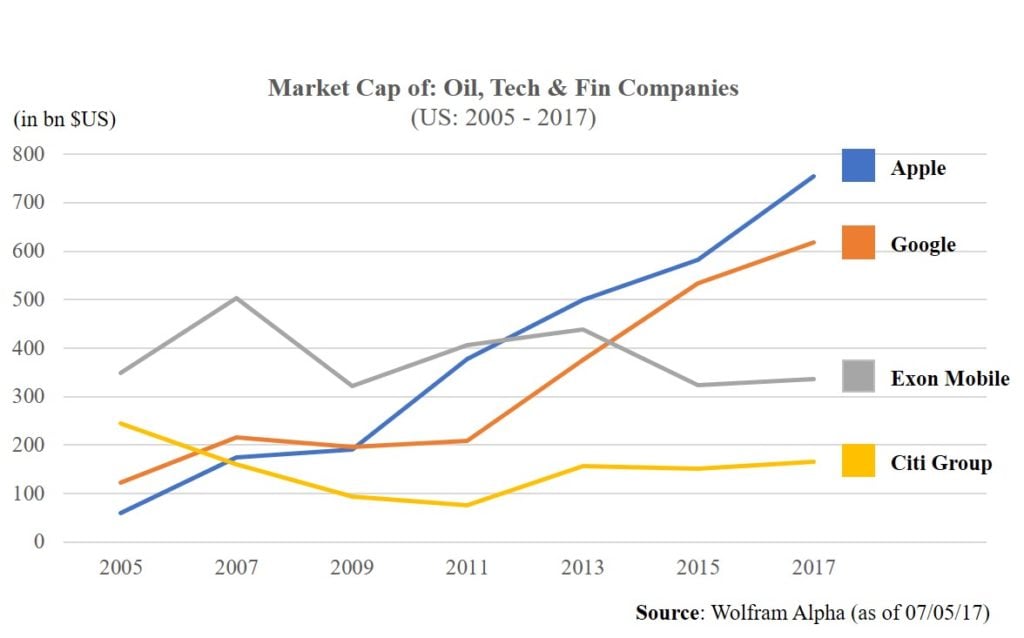
Even with this falling cost of data, the market cap of technology companies keeps increasing (as opposed to the positive correlation seen with oil companies and Brent crude). 2007 marked the point in which the world leading bank by market cap (Citi) was eclipsed by by tech players (Google and Apple). In 2011, the iPhone propelled Apple beyond Exon Mobile, to be joined by Google in 2013 (see right). Data alone cannot justify these valuations. This was echoed by Hal Varian, Google Chief Economist:
What matters more, he says, is the quality of the algorithms that crunch the data and the talent a firm has hired to develop them. Google’s success “is about recipes, not ingredients”.
Similar to the oil industry, the added value is not in the extraction of the raw material but in its refinement. However, data has more potential, with three additional properties: re-usability, transferability, and network effects.
In short, processed data cumulates (i.e. store, share, co-relate) while oil is consumed. The more data that is added, the more value that is extracted and in an age of machine learning, the better the algorithm. The problem is, data is generated by all, collected by some and understood by a few and network effects are naturally oligopolistic.
As TechFins (i.e. Amazon, Alibaba, Uber, Tencent) enter finance, the protection barriers of competition will not be licensing requirements as it was the case for banks, but proprietary algorithms instead.
The Economist analyzed the topic from an anti-trust perspective. This is both necessary and continues the oil analogy referring to the Standard Oil Co. of New Jersey v. United States case which found the oil company guilty of monopolizing the petroleum industry. The proposed action plan had two aspects:
- Use of RegTech: “Trustbusters must also become more data-savvy in their analysis of market dynamics” … “for example by using simulations to hunt for algorithms colluding over prices”.
- DataBanks: Whether self-sovereign or national, the logic is to open up data to disseminate its use and facilitate its monitoring. Given the economics of personal data value (part 1), databanks won’t be about financial gains but about practical convenience (i.e. MyInfo Singapore bank forms)
The Economist article stopped here and failed to address two subsequent questions: Data Privacy (Part 2 – below) and Data Ownership (Part 3).
Differential Content vs. Context: Limits of Privacy laws
Let me start by saying that I will not cover data privacy from a moral angle. Data sharing and collection is influenced by history (i.e. WW2 Europe), generations (i.e. Millennials & Data sharing) and technological advancements. Instead, I will articulate why today’s data privacy laws are at odds with the 21st century.
Put simply, the problem comes from the fact that the purpose of data collection has changed. Before, your age would be used for opening an account and your age for buying a product. Today, you consent to give your data for a potential future benefit that is not clear to you or the firm. Can one really consent to giving access to their information if the end purpose is not clear? This is precisely what machine learning is doing. What is more, consent is not optional. The freemium model is built around data disclosure. Opting-out of granting data access equates to being a second-class digital citizen. No google maps, Whatsapp or Youtube.
Technology companies are playing are arbitrage generated by outdated laws. In simple terms, we have inherited data privacy laws dating from the 1970’s that were influenced by external events (i.e. Nixon Watergate scandal favored the Freedom of Information Act), new technologies (i.e. increasing use of IBM mainframe computers by banks and hospitals) and with human in minds (i.e. desired to protect the content of a document or conversation).
Technology companies are interested in the context of your data and as opposed to its content. This is a reflection two factors. First, the law protects the abuse and loss of identifying information (i.e. name, social security number, personal address) increase compliance costs. Second, computers were (until now) bad at understanding content (i.e. voice, text, picture) but great at correlating context. Google did looked at your Gmail because it was easier for them to understand how often you e-mailed a specific recipient as opposed to what you said to them. The book Data & Goliath says it differently:
Computers can’t abstractly reason nearly as well as people, but they can process enormous amounts of data ever more quickly (if you think about it, this means that computers are better at working with meta-data than they are handling conversational data). […]. Computers are already far better than people at processing quantitative data and they will continue to improve.
Interestingly not all tech companies are created equal when it comes to data privacy. While certain data brokers make money from selling information (i.e. Google), others make money from collecting information from their product (i.e. Apple). Apple’s hard stance on data privacy can be understood by looking at their business model. Apple makes 69% of its revenue selling hardware, while Google generated 75% of its revenue by selling advertisements. In other words, Apple can afford the sunk cost of not selling the oil it possesses.
This has led the firm to develop the notion of “differential privacy,” which is defined as such: the statistical science of trying to learn as much as possible about a group while learning as little as possible about any individual in it.
Therefore before we engage in the upcoming gold rush, since less than 1% of the worlds data is currently analyzed, data management laws need to be reformed and reflect the incentives and business models of its participants.
Data Ownership: Incentivization of Market Participants and the Rule of Law
In preparing for this new Eldorado, looking at the history of oil ownership can teach us a few things about the future of data extraction and the creation of a data broker model used by all. The American oil rush can be explained by the Ad Coelum Doctrine, a core principle of property law:
Cuius est solum, eius est usque ad coelum et ad inferos ” or “whoever owns the soil, holds title all the way up to the heavens and down to the depths of hell”
Courts have adjusted that doctrine to allow for the development of the oil and gas industry. The doctrine’s simplicity is easily applied for hard minerals (i.e. coal) but creates a problem with volatile minerals (i.e. oil). The difficulty occurs when a landowner extracts the resources directly underneath his land, but also siphons off neighboring properties–which would be regarded as theft (see, below left).

To protect people from this potential liability, courts have used the common law notion of Ferae Naturae also known as the “Rule of Capture”. This essentially gives claim to the first person accessing it. Strong of this legal certainty an increasing number of prospector entered the market. They were in a race to extract all the resources as fast as possible. People bought small parcels of land adjacent to the large common pool of oil reserves. In doing so, they shaped entire landscape with pumpers seen until the horizon (see above right). In a decade, domestic output went from 2,000 (1859) to 10,000,000 barrels (1869).
Today, we are all participants in the data age, but only a handful of us are active participants. The economics of data (part 1) and the fragmentation of the market (we each individually produce the data) creates no incentive for people to be sovereign of their own oil. The scale of technology groups matters because they benefit from the volumes (i.e. Facebook has 1,86bn users, Tencent has 800m).
However, a combination of data privacy reform and taxations could lead to the re-imagining of the economic model of the tech giants. The oil industry also has been reformed as a result of the fact that the Rule of Capture Doctrine has generated many negative externalities as cited by Angela Staples. They included closely spaced wells, dangerous working conditions, excessive drilling, excessive production, and price drops.
We (Prof Zetsche, Prof Buckley and Prof Arner) suggested some policy considerations, aiming to solve these challenges of data-driven finance lead by TechFin players. Only if we truly value data will we create the conditions for regulators to uphold their competitive and consumer protection markets. Likewise, the public will prefer to work with data custodians as opposed to data brokers.
The future made will be made of incumbents and start-ups acting as a custodian of your information. The question is: When will you choose to be the client of a Databank?
***
This post builds upon a newly released academic research: From FinTech to TechFin: The Regulatory Challenges of Data-Driven Finance and was first published on LinkedIn Pulse.


